
Deploying a Ruby on Rails application to Google Kubernetes Engine: a step-by-step guide - Part 2: Up and running with Kubernetes
Introduction
Update: I’ve now created a premium training course, Kubernetes on Rails, which takes some inspiration from this blog post series but updated with the latest changes in Kubernetes and Google Cloud and greatly simplified coursework based on feedback I got from these blog posts. All packaged up in an easy-to-follow screencast format. Please check it out! ☺️ - Abe
Welcome to part two of this five-part series on deploying a Rails application to Google Kubernetes Engine. If you’ve arrived here out-of-order, you can jump to a different part:
Part 1: Introduction and creating cloud resources
Part 3: Cache static assets using Cloud CDN
Part 4: Enable HTTPS using Let’s Encrypt and cert-manager
Part 5: Conclusion, further topics and Rails extras
So we’ve got our resources created and sitting idle, and the Docker image of our application is built and ready to deploy. In order to deploy the app on GKE, we’ll first have to understand some basic K8s concepts. This will be a quick introduction; if you want a full-fledged tutorial check out the official documentation or Kubernetes By Example.
Kubernetes abstractions
Kubernetes adds some abstractions that are useful for deploying applications. I’ll explain just the ones we’ll be dealing with now.
Pod
The most basic abstraction is the Pod, which is a group of one or more containers. Even if you’re only deploying one container, that’s still encapsulated as a Pod.
A Pod is similar to Docker’s linked containers, but one nice difference is that when connecting to sibling containers, you simply use localhost for the hostname rather than futzing with environment variables or /etc/hosts. This works because all containers in a Pod are guaranteed to run on the same node (a node is an individual K8s worker machine in the cluster, which on GKE is a VM). However one annoying difference is there is no equivalent to --volumes-from for sharing files between containers. 😤
You should never create bare Pods directly, because they are unmanaged (if they die, nobody notices). Instead you’ll define Pod templates within other K8s abstractions that will create and manage them as part of their job.
Footgun alert: in a Pod template, if you ever want to overwrite a Docker container’s CMD, the Kubernetes field name to use is args. If you use command you will actually overwrite the ENTRYPOINT!
Good lord I spent 1/2 an hour debugging why my Kubernetes container config wasn't working and it was because k8s "command" doesn't overwrite Docker's CMD but rather the ENTRYPOINT. To overwrite CMD use "args" -.- pic.twitter.com/mcX4n4uHNM
— Abe Voelker (@abevoelker) December 12, 2017
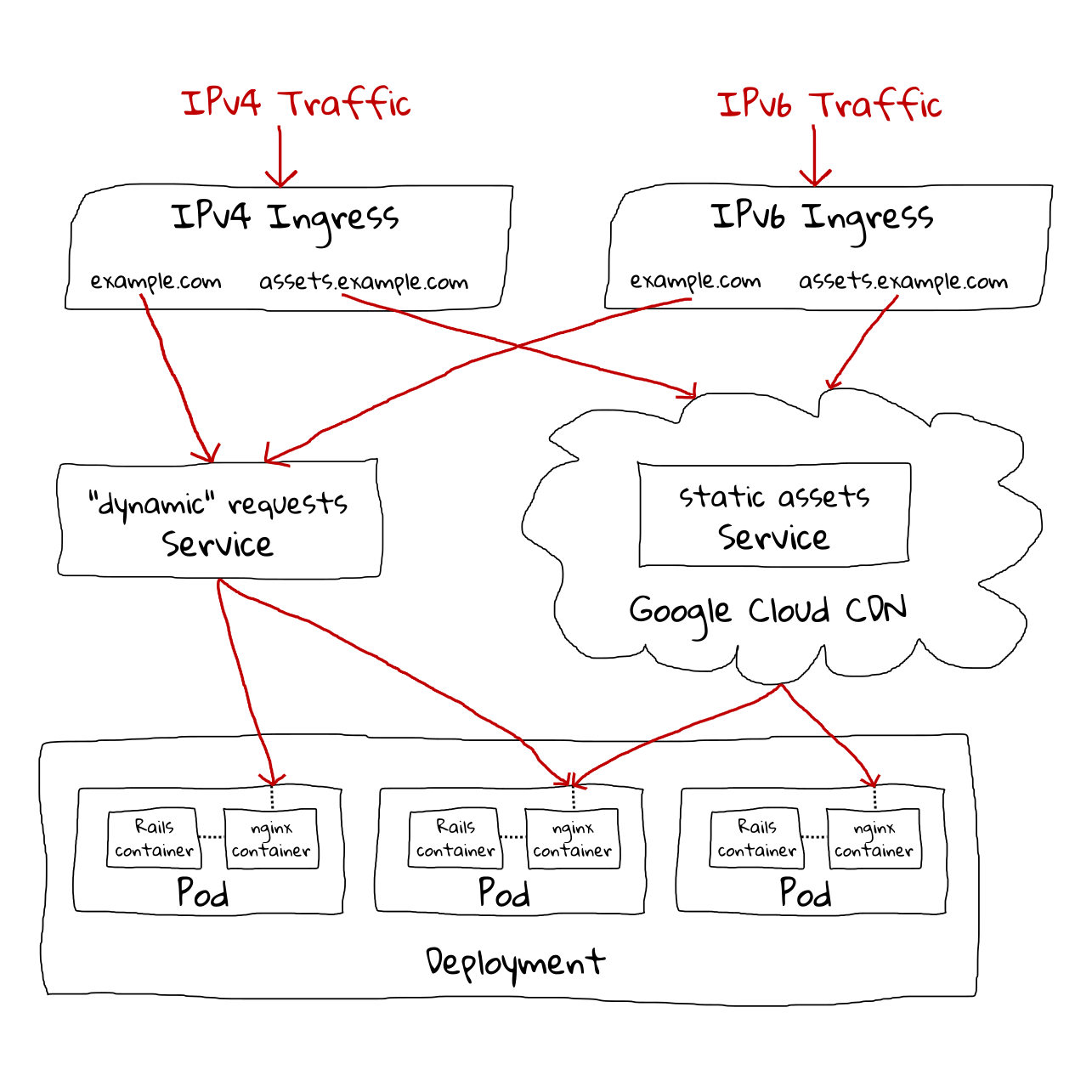
Tip: in Pod templates where the application should handle both IPv4 and IPv6 traffic, you should bind to localhost (which on most modern systems defines a loopback for both IPv4 and IPv6). This seems counter-intuitive because we think of localhost as being private, but remember Kubernetes is opening up container-local ports to the outside world for us.
Many applications default to binding 0.0.0.0, but remember that’s an IPv4 address which will only handle IPv4 traffic; binding to [::1] (the IPv6 equivalent) would likewise only yield IPv6 traffic. Without this trick your application would have to be capable of binding to both of those interfaces (or you’d have to add a custom hostname to the hosts file that does so).
Deployment
Deployments mainly tackle two concerns:
- A way to specify a desired number of Pods to be run (“replicas”1), continually ensuring that number is maintained by killing or spinning up new Pods as necessary
- Intelligently transitioning between desired Pod definitions. For example, if you have a running Deployment and then change the image of the underlying Pods, the Deployment will perform a “rolling update”2 which slowly creates new Pods with the updated definition, balanced with draining outdated Pods in equal measure until all old Pods are dead (replaced with the new definition)
Using Deployments, you can build all sorts of deploy strategies such as canary releases, blue-green, “rainbow” deploys and many others.
We’ll create one Deployment to run multiple instances of our web app and ensure they remain up.
Service
Services are a networking abstraction that logically groups a set of Pods under a label, making them accessible from inside (and sometimes outside) the cluster from a single endpoint, while load balancing3 requests. This is useful if you have have, say, a group of “frontend” Pods that need to communicate with a “backend” group - Services tame the complexity of Pods discovering and connecting with eachother.
There are different types of services which offer different exposure methods; this is a good article explaining some differences.
We’ll create two Services for this demo to expose our web app - one for static assets that the nginx container will respond to and one for “dynamic” requests that nginx will proxy to the the Rails container. Normally we’d only need one Service for this, since we only have one Deployment / one Pod type that handles both types of request, but because we’re using Cloud CDN for only our static assets, we have to split them at the Service level to make Cloud CDN happy.
Ingress
An Ingress provides external access to Services, and can provide “load balancing, SSL termination and name-based virtual hosting.” On GKE, creating an Ingress automatically creates a Google Cloud Load Balancer (GCLB) - awesome!
We’ll use two Ingresses to route public traffic to our app. This is solely to support IPv6 in addition to IPv4 as GCP requires separate Ingresses for this. Normally you’d pay extra for having to run two, but GCP doesn’t charge for IPv6 Ingresses.
ConfigMap
ConfigMaps are how you provide configuration data to Pods. “Map” because they are maps of key-value pairs. These values can be exposed to the Pod as either environment variables or mounted as files. The config values don’t have to be simple variables either - you can store entire files in config values (useful for say copying an nginx.conf).
We’ll create ConfigMaps to store some configuration info for our Pods.
Secret
Secrets store sensitive information, like passwords and private keys.
Currently Secrets are not all that secure - the information is base64-encoded and replicated across an etcd cluster. But there are future plans to make Secrets more secure, and currently the way it is templated gets the information out of version control, so it’s still a good practice to use them now.
We’ll use Secrets to store sensitive configuration info for our Pods.
Job
“A Job creates one or more pods and ensures that a specified number of them successfully terminate.” These are useful for one-off tasks that you need to be sure complete successfully.
We’ll use a Job to run our database migrations.
Kubernetes commands
To interact with our Kubernetes cluster (GKE), we’ll be using kubectl. There are a lot of available commands, but we’ll only be using the following:4
kubectl create- create a resourcekubectl apply- apply a configuration to a resource(s)kubectl get- shows basic info about a resource(s)kubectl describe- shows detailed info about a resource(s)kubectl logs- prints container logskubectl exec- execute command in a container
Kubernetes deployment
Kubernetes resource configurations are stored as YAML files called manifests.
I’ve stored all the Kubernetes manifests for our project under the deploy directory. To be precise these files are actually templates that will need to be filled in with the environment variables that we’ve been setting as we’ve went through the tutorial.
To accomplish this, I’ve written a homebrew template.sh script that uses envsubst from the GNU gettext package; this should already be installed on most Linuxes but if you’re on Mac you may need to install from homebrew. If you’re missing a variable the script will let you know and you can set the variable and try again.
It might seem weird to use a homebrew solution here but Kubernetes doesn’t ship with a templating solution,5 so I thought this would be simpler than adding another third-party program to the prerequisites to complete the demo.
Let’s run the template script now to turn the templates into ready-to-run Kubernetes manifests:
$ deploy/template.sh
deploy/k8s/configmap-nginx-conf.yml
deploy/k8s/configmap-nginx-site.yml
deploy/k8s/deploy-web.yml
deploy/k8s/ingress-ipv4.yml
deploy/k8s/ingress-ipv6.yml
deploy/k8s/jobs/job-migrate.yml
deploy/k8s/service-assets.yml
deploy/k8s/service-web.yml
Feel free to look through the manifests, particularly the Deployment which will be the backbone of our application. You may notice that there are some Secrets referenced there that we haven’t defined yet; let’s go ahead and create those now.
First let’s create the Secrets containing private keys for our service accounts:
$ gcloud iam service-accounts keys create deploy/.keys/app-user.json --iam-account $APP_USER_EMAIL
$ kubectl create secret generic app-user-credentials \
--from-file=keyfile=deploy/.keys/app-user.json
$ gcloud iam service-accounts keys create deploy/.keys/sql-user.json --iam-account $SQL_USER_EMAIL
$ kubectl create secret generic cloudsql-instance-credentials \
--from-file=credentials.json=deploy/.keys/sql-user.json
We’ll also need to store our SQL password as a Secret:
$ kubectl create secret generic cloudsql-db-credentials \
--from-literal=username=proxyuser --from-literal=password=foobar
Run the database migration
At this point everything should finally be ready for us to bring up our application!
The first thing we’ll want to do is run the database migration to initialize our database. We’ll do that by creating a Job:
$ kubectl apply -f deploy/k8s/jobs/job-migrate.yml
job "captioned-images-db-migrate" created
Note that we used kubectl apply instead of kubectl create; we could’ve used kubectl create but kubectl apply is smart enough to create a new resource if it doesn’t exist, or to modify an existing resource if the configuration we’re applying doesn’t match what currently exists.
We can now watch the progress of our Job with:
$ kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
captioned-images-db-migrate 1 0 3s
and see the Pods it created with:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
captioned-images-db-migrate-qzkdt 0/2 ContainerCreating 0 15s
Note: your pod names will be different than mine throughout the tutorial
Tip: if you’re watching for changes, instead of re-executing kubectl get pods over and over you can do kubectl get pods -w (or --watch) which will poll indefinitely and automatically print changes
What we should see is the Job transition from 1 desired / 0 successful to 1 desired / 1 successful, and the Pod transition from ContainerCreating status to Running, then finally Completed status with 0/2 in the ready column.
Unfortunately what we actually end up with is this:
$ kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
captioned-images-db-migrate 1 0 5m
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
captioned-images-db-migrate-qzkdt 1/2 Completed 0 5m
This is due to a combination of Kubernetes currently poorly handling sidecar containers in Jobs, and GKE needing the proxy sidecar container for database connections in the first place as well as some convolution with how it traps signals and emits exit codes.
There are multiple workarounds to this issue, but they are pretty hacky and would’ve made the manifests overly confusing for a learner. Instead I opted to deal with a little unpleasantness now - I promise the rest of this will go smoother!
So what we’ll do is verify that our migration actually ran successfully by viewing the output of the Rails container:
$ kubectl logs pods/captioned-images-db-migrate-qzkdt -c captioned-images-migrate
Created database 'captioned_images'
== 20180123053414 CreateCaptionedImages: migrating ============================
-- create_table(:captioned_images)
-> 0.0090s
== 20180123053414 CreateCaptionedImages: migrated (0.0091s) ===================
Then we’ll delete the Job and put this unpleasantness behind us:
$ kubectl delete jobs/captioned-images-db-migrate
job "captioned-images-db-migrate" deleted
Bring up the application
Now that our database is migrated, we can finally bring up the application. This will be really easy as kubectl apply accepts a directory so we can simply feed it the whole directory that contains the rest of our manifests:
$ kubectl apply -f deploy/k8s
configmap "nginx-conf" created
configmap "nginx-confd" created
deployment "captioned-images-web" created
ingress "captioned-images-ipv4-ingress" created
ingress "captioned-images-ipv6-ingress" created
service "captioned-images-assets" created
service "captioned-images-web" created
We don’t have to worry about applying manifests in order - Kubernetes will figure things out.
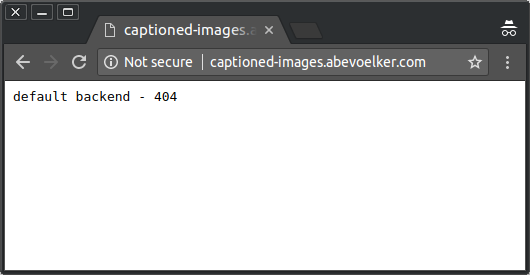
Now we can grab a cup of coffee, and in a couple minutes the site should be online at the DNS address you selected. While the Ingress is still spinning up, you’ll see a blank page with “default backend - 404”6 until the backend app becomes available:
If you want to keep an eye on things as they progress you can use kubectl get:
$ kubectl get cm,deploy,ing,svc,po
NAME DATA AGE
cm/nginx-conf 1 1h
cm/nginx-confd 1 1h
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/captioned-images-web 2 2 2 2 1h
NAME HOSTS ADDRESS PORTS AGE
ing/captioned-images-ipv4-ingress captioned-images.abevoelker.com,assets-captioned-images.abevoelker.com 130.211.47.102 80 1h
ing/captioned-images-ipv6-ingress captioned-images.abevoelker.com,assets-captioned-images.abevoelker.com 2600:1901:0:f... 80 1h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/captioned-images-assets NodePort 10.51.243.119 <none> 80:31477/TCP 1h
svc/captioned-images-web NodePort 10.51.252.114 <none> 80:31468/TCP 1h
svc/kubernetes ClusterIP 10.51.240.1 <none> 443/TCP 1d
NAME READY STATUS RESTARTS AGE
po/captioned-images-web-54f7df6f9-fpfdg 3/3 Running 0 1h
po/captioned-images-web-54f7df6f9-hnxcj 3/3 Running 0 1h
Note: in the above command, cm is short for configmap, ing is short for ingress, etc. - you can see all shortnames with kubectl get --help
Or drill down into more details with kubectl describe:
$ kubectl describe ing
# long output redacted
But it shouldn’t take long for the complete site to become available:
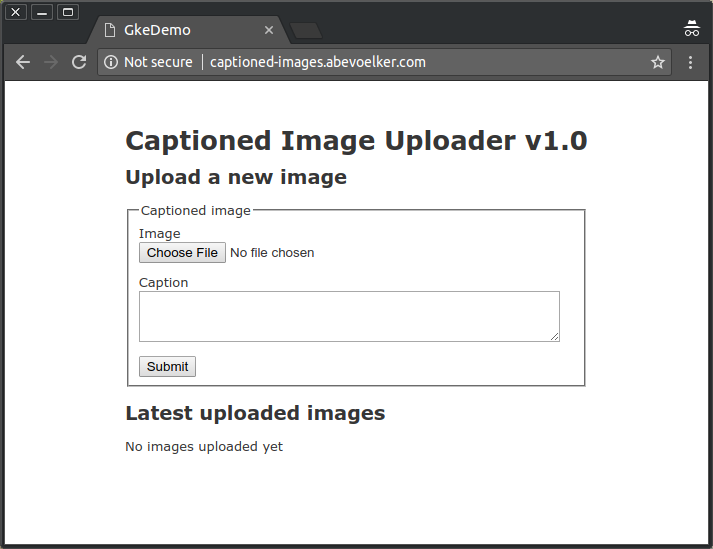
Go ahead and try uploading a picture with a caption now - everything should be working as expected!
If you only have IPv4 like I do you can test IPv6 connectivity using a site like ipv6-test.com.
Redeploying the application
Now that we’ve successfully deployed our application, what do we do when we need to make a change?
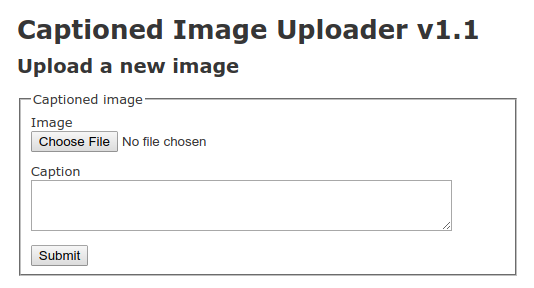
Go ahead and change the “v1.0” in the <h1> to “v1.1”. Then commit the change and submit a new build:
$ export COMMIT_SHA=$(git rev-parse --verify HEAD)
$ gcloud container builds submit --config cloudbuild.yaml --substitutions=COMMIT_SHA=$COMMIT_SHA
Then when the remote Docker build is complete, we’ll run our template script to update the Kubernetes manifests then run kubectl apply to update the Deployment:
$ deploy/template.sh
$ kubectl apply -f deploy/k8s/deploy-web.yml
Alternatively, in scenarios like this where only a Docker image has changed, we can use kubectl set image:
$ kubectl set image deployment/captioned-images-web captioned-images-web=us.gcr.io/$PROJECT_ID/gke_demo:$COMMIT_SHA
After a short wait while the Deployment updates, voilà:
Note: kubectl set image obviously won’t update your local manifest file with whatever the current version of the Deployment looks like. To dump the current version of a resource as YAML, we can do:
$ kubectl get deployment/captioned-images-web -o=yaml
However be aware a lot of extra fields will come back that you probably won’t have in your own hand-created manifest file, as this is a “complete” snapshot of the resource.
Warning: if your application change is only an update to a ConfigMap, be aware that redeploying a Deployment that depends on it (with no other changes to the Deployment) will result in no change to the Deployment. In short the Deployment won’t detect that the ConfigMap changed.
I usually add a junk environment variable to one of the Deployment’s containers in this scenario, which will force a fresh redeploy that picks up the ConfigMap change.
End Part 2
That’s all for Part 2.
Join me next in Part 3 where we’ll cache our static assets using Google Cloud CDN!
Thank you
HUGE thanks to my reviewers, Daniel Brice (@fried_brice) and Sunny R. Juneja (@sunnyrjuneja) for reviewing very rough drafts of this series of blog post and providing feedback. 😍 They stepped on a lot of rakes so that you didn’t have to - please give them a follow! 😀
Any mistakes in these posts remain of course solely my own.
Footnotes
-
Internally, Deployments use another K8s abstraction called a ReplicaSet but you shouldn’t need to worry about that unless you have advanced requirements. ↩
-
The default
RollingUpdateupdate strategy is even interchangeable; you can instead chooseRecreatewhich will kill all existing Pods before bringing up any new ones. ↩ -
Although load balancing can be disabled, creating a “headless” Service ↩
-
View the CLI help by executing a bare
kubectlor visit the online manual to see all available commands ↩ -
There are many, many solutions that have sprang up in the community to fill the gap, but many are tied into larger tools or opinionated workflows (e.g. some also want to de-dupe sections of manifests). The Kubernetes maintainers seem to be aware of the situation but for now there is no official integration.
A mature Kubernetes deployment will probably end up using Helm, which comes with templating, but for a tutorial I don’t want to over-complicate things. ↩
-
You may also see a 502 or 500 error briefly while the Ingress is coming online and checking the
readinessProbe.Our container is configured to do a
SELECT 1when the load balancer hits/pulse, which ensures that our Rails server can reach our SQL database (i.e. it’s ready to serve traffic). If you want to learn more about Kubernetes’ probes (readinessProbeandlivenessProbe), read the documentation. ↩