
Cure for the Plague: A Theoretical Progress / OpenEdge ABL Migration Plan

I think
my opinion
on Progress OpenEdge ABL (henceforth known as “the Plague”) as a programming
language / DBMS is well known, but here is a short summary in case you missed it:
Progress made a bet a long time ago (back in the 1980s) that the future of programming languages were going to be languages with a huge amount of global keywords bolted into the syntax, which handle complex processing tasks for the programmer in a closed/magical way (the programmer would have no idea how it really happens, by design), including database access. They called this a “4GL”, or fourth-generation language.
Obviously, Progress lost that bet. What Progress belittlingly refers to as the “3GL”s (e.g. C/C++, Java, C#, Perl, …), which have a much lighter dictionary of reserved keywords and ‘bolted-on’ syntax for performing tasks, have been proven by industry to actually be much better designed due to their modularity and extensibility. This extensibility, which allows programmers to easily create powerful external libraries and frameworks, fulfills what Progress sought to do 25 years ago but without the added headache of coupling implementation details to the language specification (I use ‘specification’ lightly, since there really is no language specification publicly available for OpenEdge that would allow one to write a compiler for it).
In my opinion, most modern shops that use Progress OpenEdge ABL probably wish there was a way to get away from it, since in today’s modern world it doesn’t take very long to hit the limits of a language that takes the exact opposite design approach that the rest of the world takes. The rest of the world is busy creating all sorts of dazzling libraries and frameworks that make programming useful, efficient and exciting while OpenEdge customers are stuck with whatever closed-source, cheap imitation solution Progress Software Corp. is able to create and bolt on to the language, in an attempt to re-create the popular thing from 4+ years ago. Not to mention the exorbitant licensing costs for the pleasure of all of the above…

Some people think that OpenEdge ABL is still worth saving, but not me. The
only remedy to this problem, in my opinion, is to migrate completely away from
the OpenEdge platform. Read on for the migration plan (henceforth known as
“the Cure”).
Migration Language Requirements
Having decided to migrate, the next step should be to define what capabilities and features to look for in a target migration language. What do you think is important to have? Here is what I came up with:
- Language must support object orientation (and primarily be oriented that
way)
- I know functional languages are all the rage now, but when migrating from a procedural language the best next step is OO as it extends the existing procedural paradigm.
- Data access should be able to be object-oriented as well (objects should be
persistable)
- If one is primarily programming in OO, it makes since to fetch and persist objects in the same manner. This might be handled by using an object-oriented database directly, or by an object-relational mapping framework (which maps objects to a relational database). More on the latter point in the next section.
- Should be CRUD-friendly
- OpenEdge is primarily data-focused. However, data access is atrocious - gathering data into cohesive units to make useful decisions upon takes a lot of fine-grained table querying and joining on the developer’s part due to OpenEdge’s limitations. OpenEdge developers waste a lot of time coding these CRUD operations over and over entirely by hand, creating repeated code blocks all over the place (which is a more error-prone process and creates code that is resistant to change and expensive to update), using fine-grained scalar details of the tables involved. An optimal target language should make CRUD a much simplified process, but still have the ability to drop down in to fine-grained details where necessary.
- Language must be able to swap data stores in a modular fashion (no tight
coupling between database and language)
- Getting locked in to a specific database is a form of tight coupling (look at what happened when Oracle bought out MySQL).
- Should have good support for Web application development
- Due to the aforementioned focus on data-access/CRUD that OpenEdge has, it is no surprise that many companies (mine included) that use OpenEdge have begun moving many programs to WebSpeed (i.e. server-side OpenEdge ABL). It is an efficient way to provide a lightweight and well-presented interface to the data for customers.
- Should not be coupled to a specific operating system
- Like requirement #4, this is another form of coupling. In today’s day and age it shouldn’t be tolerated.
This is the basic list of capabilities that I think are important. If you have anything to add or disagree with, please post in the comments section.
Object-Relational Mapping
I would like to take a minute to expound on a specific topic before continuing any further: object-relational mapping (ORM).
Before I even started to concretely define exactly what I needed in a migration language, I already knew that the two most important things were that the language as well as the database access be object-oriented. During my senior year at university, I was able to use NHibernate a little bit for one of my final class projects. It introduced me to the ability to nearly transparently fetch and persist objects from a relational database (in this case MySQL). In other words, object-relational mapping. The beauty of having a framework create complex database queries - filtering, sorting, joining tables, etc. - just by using some simple macro keywords on object properties and methods, and returning a collection of objects, is truly a thing of beauty. In addition, by using a relational database at the core, one is able to quickly write simple, scalar-based queries for retrieving data when you really don’t need to pull out entire objects. In other words, you can have both the speed of fine-grained scalar queries and the power and flexibility of object-based queries.
However, I have noticed some dangerous topics crop up on PSDN and other OpenEdge discussion areas that make it seem that an object-relational mapping framework for OpenEdge ABL is something to aspire to, and furthermore will be some sort of magic bullet for carrying on using OpenEdge into the future. Let me put it bluntly: ORM is a very complex thing. One feature here and another feature there (e.g. a Collections interface like Java has) added to OpenEdge ABL will not make it able to do ORM cleanly. There are some serious issues that have to be worked out; these issues require a language that is very strong in its object-oriented capabilities in order to overcome them. OpenEdge is not, and probably will never be strong enough in OO to be able to handle something like this as cleanly as many other languages have already made it. I could write another entire post on this subject in more detail to explain why some popular opinions on OpenEdge ABL getting ORM are either not well-founded or simply Bad Ideas, but I will not bother wasting the energy.
Now that I’ve gotten that off my chest, let’s continue on with how to break out of the OpenEdge system.
Jailbreaking
Having created a wishlist of features to have, we now have to face reality. We cannot simply click our heels together three times and be completely on a new language and data store. There will undoubtedly be a transitional period between OpenEdge ABL and the target, during which they will have to work together. I foresee two different ways to accomplish this:
- Identify OpenEdge subsystems that can be replaced. Completely rewrite these subsystems in the new language, and migrate the OpenEdge data over to the new data store. Then, flip a switch to start running the subsystems entirely in the new language. The replaced OpenEdge subsystem can then be removed. If there still exists OpenEdge subsystems that need to interact with this new one, then an Enterprise Service Bus (ESB) such as a JMS (e.g. Apache ActiveMQ) can be used to send messages between them across the differing datastores.
- If the new language can connect to the OpenEdge database, then write programs in the new language in small pieces that can run alongside existing Progress OpenEdge ABL programs within the same subsystem (they will both fetch and persist from/to the same OpenEdge database(s)). Once the entire subsystem has been sufficiently converted, then the OpenEdge database data can be migrated to a data store that the new language can use more efficiently (and the legacy OpenEdge data can be destroyed). At this point, #1 can take effect - the switch gets flipped, etc.
Clearly option #2 would be the more useful option, since the conversion can be done in smaller steps, allowing for better integration testing along the entire process. If you are wondering how #2 is even possible, let me draw you a picture:
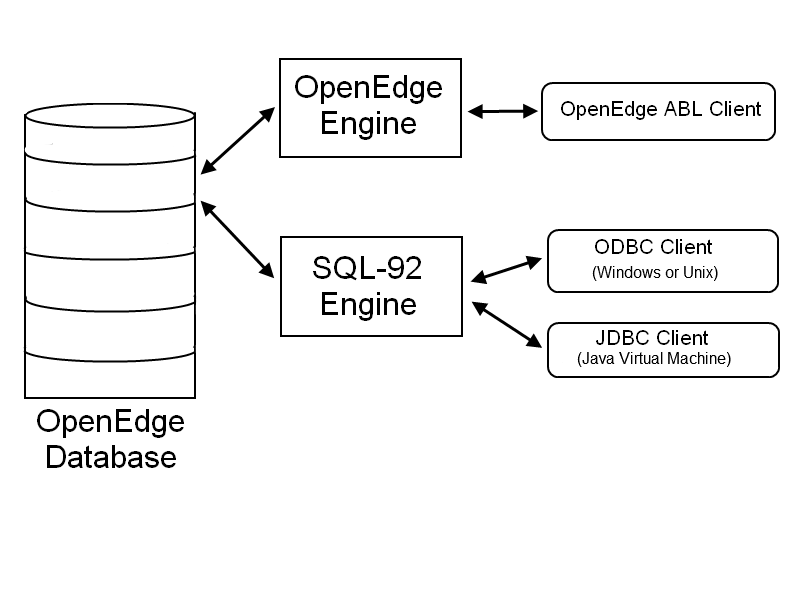
In case you didn’t know, OpenEdge allows one to run a SQL-92 engine concurrently with the OpenEdge engine (see SQL Development and SQL Reference OpenEdge documentation for more info)! This small but amazing fact means that you can run non-OpenEdge programs against the OpenEdge database using ODBC or JDBC drivers; these programs will simply see SQL datatypes and not know the true, horrible secret of what lies beneath.
I am going to concentrate on migration options that satisfy method #2 above, since I believe that it is the most flexible. In addition, I have found from reading the aforementioned SQL manuals that it seems that the JDBC driver is the more supported/robust method of connecting to the OpenEdge databases using SQL. I have come to this conclusion by seeing the deprecated ODBC examples in the handbooks as well as anecdotal evidence from perusing online discussions that the ODBC driver is not as fast as the JDBC one (please correct me in the comments section if I am incorrect in this assumption!).
Potpourri
Now that we have both a list of goals and a list of limitations, it is finally time to start researching viable migration target languages. I have restricted myself to languages capable of running the JDBC drivers, however, so my choices are limited to languages that run on top of a Java Virtual Machine (JVM). Keeping this restriction in mind, these are my top three choices, in no particular order:
- Java
- Groovy
- Ruby (JRuby interpreter)
Here is how each of the choices match up against the list of requirements/desired features I had written:
Java
- Language must support object orientation (and primarily be oriented that
way)
- Check.
- Data access should be able to be object-oriented as well (objects should be
persistable)
- Java Persistence API (JPA) 2.0 seems to be the new direction for ORM on Java; it appears to be quite powerful. Hibernate used to be the popular choice, but is now an extension of JPA2.
- Should be CRUD-friendly
- I don’t think JPA2 itself is very CRUD-friendly; I don’t know of any extensions that make it that way either (please correct me if I am wrong on this).
- Language must be able to swap data stores in a modular fashion (no tight
coupling between database and language)
- Check - JDBC.
- Should have good support for Web application development
- Check - Apache Struts; many, many others.
- Should not be coupled to a specific operating system
- Check - JVM.
Groovy
- Language must support object orientation (and primarily be oriented that
way)
- Check.
- Data access should be able to be object-oriented as well (objects should be persistable)
- Should be CRUD-friendly
- Grails nails this.
- Language must be able to swap data stores in a modular fashion (no tight
coupling between database and language)
- JDBC is primarily used.
- Should have good support for Web application development
- Should not be coupled to a specific operating system
- Check - JVM.
JRuby
- Language must support object orientation (and primarily be oriented that
way)
- Check.
- Data access should be able to be object-oriented as well (objects should be
persistable)
- Very strong - there are several popular ORM frameworks, including ActiveRecord and DataMapper.
- Should be CRUD-friendly
- Ruby on Rails nails this.
- Language must be able to swap data stores in a modular fashion (no tight
coupling between database and language)
- Check. Can use old methods like straight JDBC or try new things like DataObjects
- Should have good support for Web application development
- Should not be coupled to a specific operating system
- Check - JVM.
The Winner
For my own requirements, I see JRuby as the best choice. The main two features that convinced me are the strong ORM support and the power of Ruby on Rails for performing Web development and CRUD operations. It also seems like a language that legacy developers that are new to OO wouldn’t have too much trouble picking up - it doesn’t require a lot of the heavyweight OO design knowledge that a language like Java requires. Also, because JRuby runs on the JVM, one can run Java code in-line with Ruby code, if so desired (of course, Groovy has this same feature, and Java can run Groovy or JRuby JVM bytecode as well, so it isn’t really unique to JRuby).
Which ORM?
Ruby has several choices in regards to ORM. However, there are two choices
that are the most popular: ActiveRecord
and DataMapper. These two choices are
rooted in two different design patterns originally defined by Martin Fowler in
his book,
Patterns of Enterprise Application Architecture.
ActiveRecord
ActiveRecord is defined by Fowler as: “An object that wraps a row in a database table or view, encapsulates the database access, and adds domain logic on that data.”
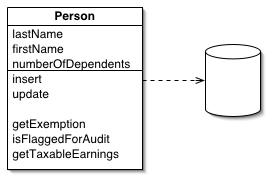
ActiveRecord is a relatively simple concept of ORM. The idea is that a class maps directly to a database table, and the class is responsible for implementing all of the database operations related to itself (insert, update, etc.).
In relation to Ruby, the ActiveRecord framework is the well-known face of Ruby ORM. It has been around for a long time, and was coupled directly to Ruby on Rails until only very recently.
In regards to OpenEdge, there would have to be an adapter written to wrap the JDBC driver in order to conform to the ActiveRecord framework API. Amazingly, some Parisians have already written such an adapter and released the source on GitHub under the open-source MIT license! Major kudos to them.
DataMapper
DataMapper is defined by Fowler as: “A layer of Mappers (473) that moves data between objects and a database while keeping them independent of each other and the mapper itself.”
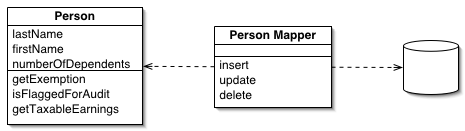
DataMapper is a more complex form of ORM than ActiveRecord. From the Fowler illustration, it is clear that the separation of objects and their mappings creates a very powerful design mechanism, which does not limit developers to a 1:1 mapping between classes and database tables. One can see that this makes it more useful for supporting legacy database schemas, where one already has a pre-defined database schema and is trying to map it into objects (which is backwards when compared to most modern ORM use-cases, where developers are creating database schemas to fit their already-defined classes).
In relation to Ruby, the DataMapper framework is a newer framework, but has gained a lot of traction. The new version of Rails (v3) is no longer tied in with the ActiveRecord framework - it is now ORM-agnostic. This means that DataMapper integration can be achieved much easier and more cleanly than it used to be.
In regards to OpenEdge, like ActiveRecord, there would have to be an adapter written in Ruby to wrap the JDBC driver to make it implement the DataMapper framework API (called a DataObject). There is currently no such adapter openly available.
My Choice
I believe that DataMapper is the best migratory choice for large OpenEdge installations. ActiveRecord is much too simple to be able to handle the legacy schemas that OpenEdge developers have to deal with, which certainly do not fit the 1:1 mapping (class:table) that ActiveRecord requires. DataMapper, on the other hand, has good support for legacy schemas.
Roadmap (Illustrated)
Now that all of the tough decisions have been made, it’s time to review our migration game plan! I’ve drawn a few diagrams that should help illustrate some of these concepts.
Step 0
This is what I assume most OpenEdge developers will be starting with. All programs are Progress/OpenEdge code. All data are held in native OpenEdge databases.
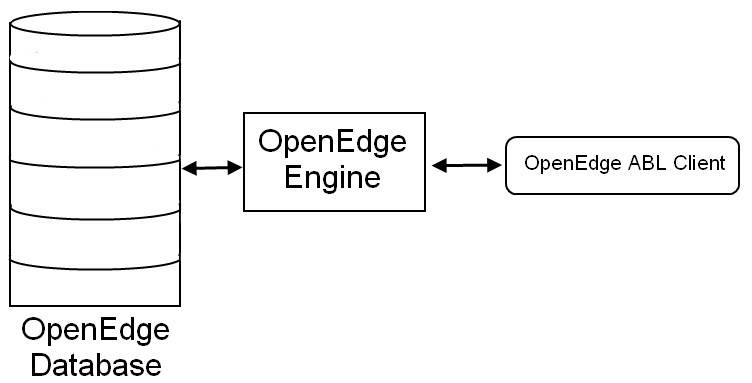
Step 1
Begin to migrate some programs over to Ruby. The database schema should be
able to stay the same - DataMapper mappings will have to be created to map
tables into Ruby objects. Ruby doesn’t know it is accessing an OpenEdge
database - the OpenEdge SQL-92 engine and JDBC driver make it think it is
connecting to a native SQL database. However, a DataMapper DataObject wrapper
(do_openedge) will have to be written to allow DataMapper to use
the JDBC driver to access the OpenEdge database
(see existing wrappers).
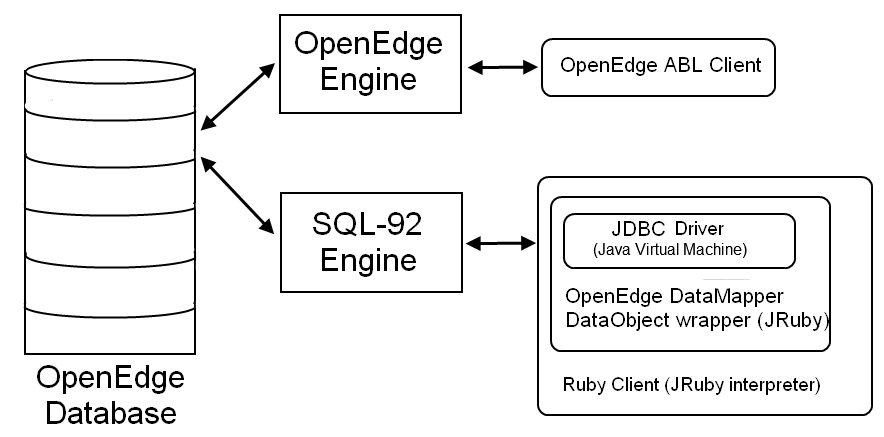
Step 2
As DataMapper objects begin to mature, and subsystems become fully “Ruby-ized”, it would be prudent to move their data to a native SQL database in order to speed up the data access. Holding the data in a native Progress/OpenEdge database will undoubtedly be a little slower due to the OpenEdge to SQL conversions that the SQL-92 engine has to make in real-time. Note that programs can still talk to eachother, even though they are using different databases, by using an ESB (e.g. a JMS like ActiveMQ). Also note that the migrated Ruby code does not require a JDBC driver anymore; it could be ran on the native C Ruby interpreter (MRI) for instance, assuming MRI DataObject wrappers are available for the new database.
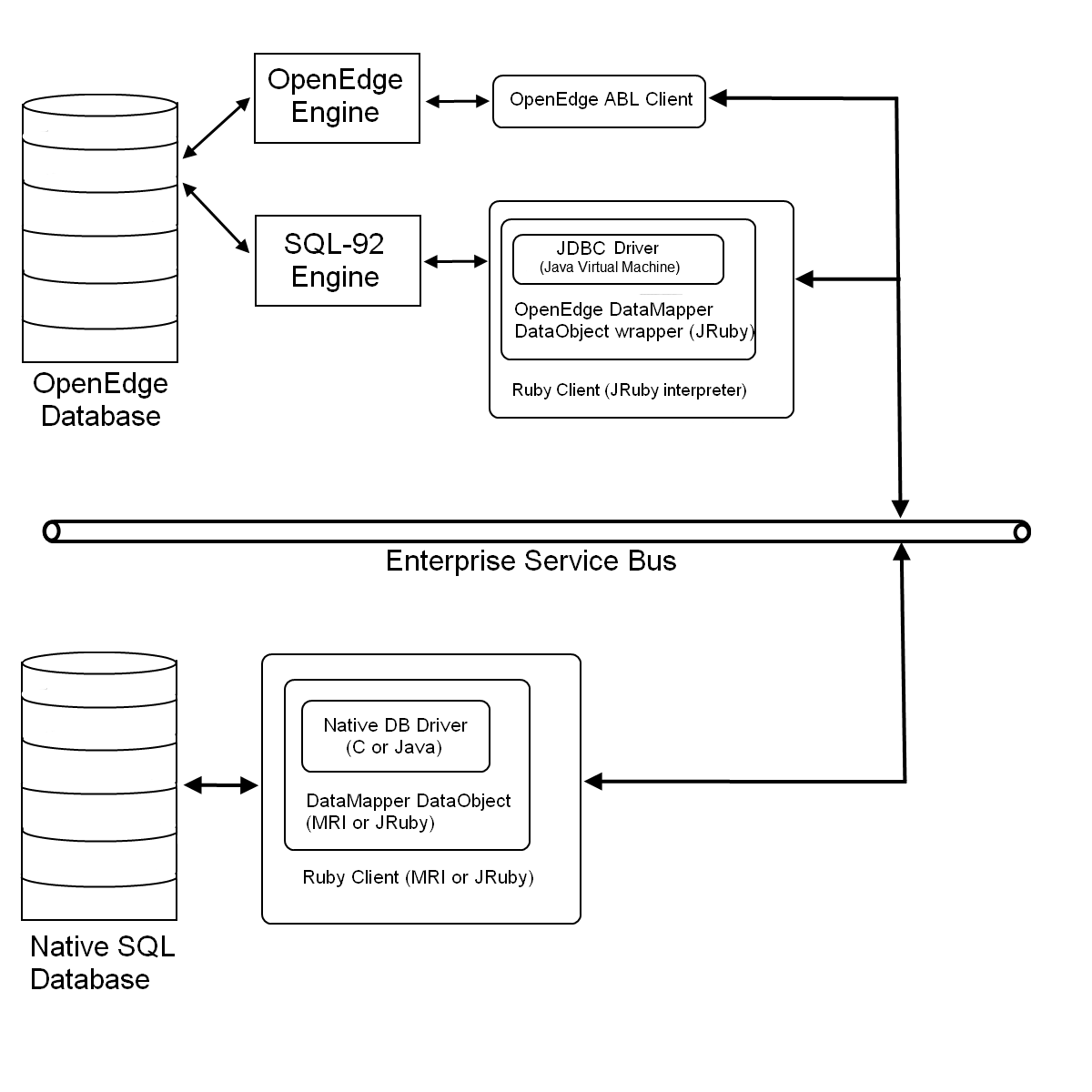
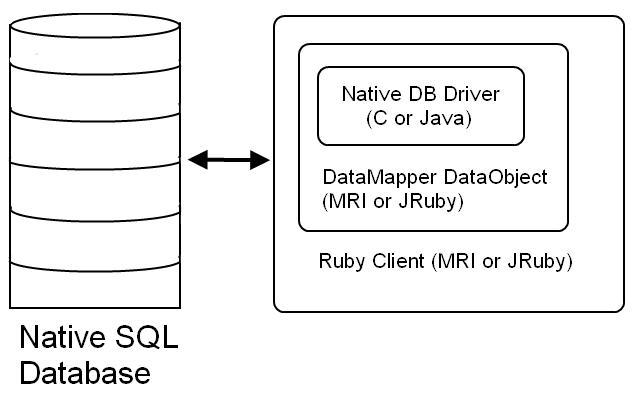
Step 3
Programs are fully migrated to native Ruby; data is fully migrated to native SQL database(s). The database schema and their DataMapper mappings may still have to be cleaned up from legacy schema format to increase efficiency (e.g. 2 or more tables when only 1 table is needed).
Proof of Concept
Here is a proof-of-concept Ruby code snippet that illustrates how an external
language can access OpenEdge data. This code must be executed from JRuby in
order to make use of the DataDirect JDBC drivers. You will have to add the
referenced .jar’s to your $CLASSPATH as well (they came bundled
with my OpenEdge 10.1C installation). They are, unfortunately, proprietary
software so I cannot attach them to this posting. Also, you obviously have to
have your OpenEdge database set up for SQL access.
require 'java'
require 'openedge/base.jar'
require 'openedge/openedge.jar'
require 'openedge/util.jar'
import 'com.ddtek.jdbc.openedge.OpenEdgeDriver'
#Fill in the connection information:
USERNAME = "sqluser"
PASSWORD = "sqlpass"
HOSTNAME = "localhost"
SERVNAME = "sportssv_d"
DBNAME = "sports"
begin
conn_str = "jdbc:datadirect:openedge://" + HOSTNAME +
":-1;databaseName=" + DBNAME + ";serviceName=" + SERVNAME
conn = java.sql.DriverManager.getConnection(conn_str, USERNAME, PASSWORD)
stmt = conn.createStatement
rs = stmt.executeQuery("SELECT * FROM \"SPORTS\".\"PUB\".\"customer\"")
while (rs.next) do
puts rs.getString("name")
end
rs.close
stmt.close
conn.close()
end
puts 'Done!'
Final Thoughts
In this posting I have attempted to illustrate a relatively thorough migration path away from Progress OpenEdge ABL. I hope that I have succeeded, and you have found this to be useful information (if so, please leave a comment!). I would also like to hear from people who have already performed or are planning to perform a migration away from Progress OpenEdge ABL.
I plan on taking the next step to improve this migration process myself, which is to write the Ruby DataObject that will implement the DataMapper API for the DataDirect OpenEdge JDBC drivers. I will update this posting when that step has been completed! It might take me a while, though, as I am new to Ruby. Wish me luck!
Update: The Ruby adapter has been completed. Enjoy!