
Email’s successor: the personal log and inter-personal protocol
Recently on my Twitter I’ve been seeing some buzz about a new email app called HEY. It seems to improve some ergonomics with traditional approaches to email, like moving receipt emails to a “paper trail” area, better screening of new contacts, and some other things.
Fundamentally though, it’s still email under the covers. This made me wonder what an evolution of what email actually is would look like.
Maybe it would help to consider where email is already evolving. Email began as exchanging plain text electronic letters between humans but now it is used for so much more.
For example, every time you place an online order you immediately get an order receipt, sent from a machine. When your order ships you get an update with a tracking number. As your shipment proceeds towards your house, you get tracking updates until the item arrives. This isn’t traditional correspondence between humans any more, this is data exchange.
Data schemas
Google had in fact already recognized this evolution and introduced special markup that annotates the unstructured text and image format of email into structured data. When a sender includes this structured data in an email, Google’s email service Gmail recognizes the type and can display display special “actions” and “highlights”.

Example Gmail "action"
This structured data vocabulary is the same approach that Google advises web developers to use to help its crawlers accurately understand content across the Web by the way. For example, an online store annotating a product’s page with an Offer may give you a snippet like this in Google search results:
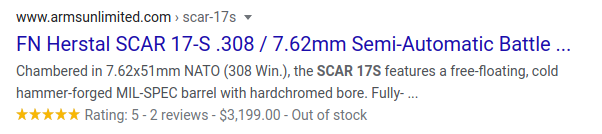
Searching Google for a specific product may return rich results like this
Applying data schemas to mail messages is a rich vein that hasn’t been fully explored yet, and I think could enable new types of data to be stored that don’t fit in the mail-like mold. I’ll give some examples further down.
Public-writable log
When I think of email as a data structure, I think of it as a public-writable log. Anybody who has my address is allowed to append to my log, given they pass some basic filtering (e.g. spam, size of message).
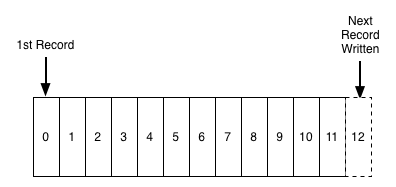
Log data structure
I think this is the key insight of email and definitely worth keeping in the next evolution.
Data sharing
What email doesn’t currently have is a way to share access to your data with others.1
What I think would be interesting is to be able to scope queries to certain pieces of data, and give read access to third parties for this data.
Let me give an example.
Right now, when I’ve placed online orders on various websites, I get a wide mix of different email notifications. Almost all of them email me a receipt for the order immediately. Most of them email me when the order ships. Some of them email me updates every time the status of the parcel changes.
Just to cover my bases, I’m also signed up for USPS Informed Delivery®, UPS My Choice®, and FedEx Delivery Manager®, so that I get notified whenever a package is scheduled to arrive at my address regardless of who it’s from (I don’t like surprises!).
It’s all very scattershot, and to keep track of what’s coming and going I’m usually jumping between emails, comparing tracking numbers here to order information over there.
What would be nice is if I had some personal dashboards, say one for Orders and one for Postal Mail that showed me the status of all my orders across all vendors, and all the postal mail that would be arriving soon (with hyperlinks between Orders and Postal Mail even). This could be either something I build myself, or a third party service that I allow keyhole access to just my orders and shipments from my personal log.
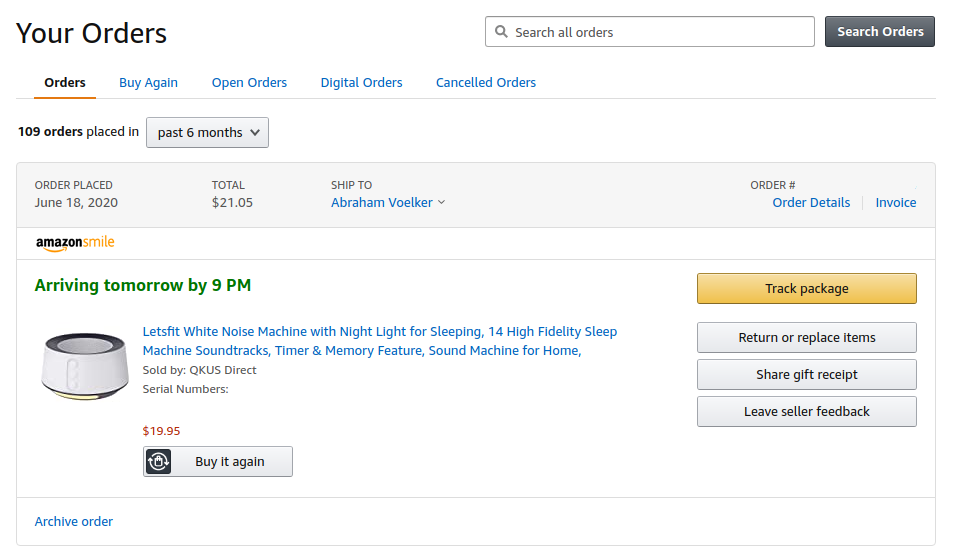
What if you had an Orders dashboard like Amazon's, but for all your online orders?
This may not sound that appealing if 99% of your orders come from Amazon. But when you order from a wide array of online shops, it could be useful. In the current climate of gun buying for example, I’ve had to use spreadsheets to keep track of what’s arriving from all the various vendors that I order from!
I unironically love that gun-related shopping was spared the consolidation of Amazon et al and you still commonly buy gear from Geocities-esque sites like it's 2003 https://t.co/HWvZpXQAuK pic.twitter.com/Drez8WkbTQ
— Abe Voelker (@abevoelker) October 15, 2019
I’ll give more examples in the following sections.
Expanding data scope
Right now there is a lot of personal data that doesn’t fit into email or a mail-like messaging system that would be a good fit for a personal log / database.2
For example, I’ve moved addresses several times over the last decade. Every other year or so I’ve seen a new optometrist, and I always opt to get those laser retina scans done. But I’m certain that every time I’ve switched to a new optometrist, there is no history carried forward from the previous optometrist - I have a bunch of retina scan records scattered across multiple offices.
What would be nice is if there was a “medical” section of my personal log, and my optometrist could (with permission) append my latest retina scan to my log, and (with permission) pull previous scans out for comparison. This way I’m the primary hub, and owner, of my own medical data.
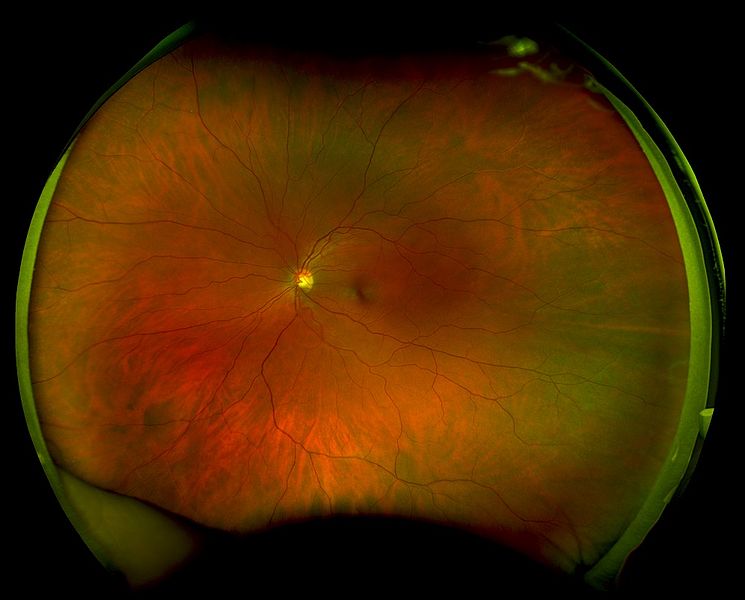
Optomap retinal scan from Wikipedia
Obviously the above scenario could also apply to doctor and dentist visits.
Example - changing mailing address
On the topic of changing addresses, if you’ve ever moved I’m sure you’re familiar with having to update all the various services you use with your new mailing address, and how you’ll almost certainly miss some.
Imagine if you could annotate your personal log with your current mailing address. When you move, you simply update this annotation, and authorized third parties are able to pull the new data (imagine something similar to a webhook).
Put another way, you could think of it as a rudimentary “home address DNS”:
i've often wanted home address DNS.
— Petulant Fig Nemesis (Mark 11:12-14) (@mwotton) May 30, 2017
Example - bank accounts and financials
Money is another fundamentally personal bit of data that would be interesting to include in the personal log.
What if your bank account and credit card ledgers were synchronized to your personal log? Instead of getting an email with a PDF or CSV statement at the end of the month, each individual credit or debit was immediately replicated to your log?
At the very least, I’d be grateful to have the full history of my bank account(s) in my log, because for some reason the banks I use seem to not show transactions past about a year.
And if my employer could attach my W-2 to my personal log (or schools attaching 1098-T, etc.), couldn’t filing taxes be as simple as running a rollup query against my (and/or my spouse’s) data? At least as a first approximation.
Open question - other data?
I’m curious what other type of data could fit in the personal log. On some occasions I’ve had to find my vehicle’s license plate number and VIN; previously I’ve had to search my email for PDF scans of insurance quotes I’ve gotten, but could this data live in the log as a first-class citizen?
Can the personal log be adapted to fit generalized notes, like people used to (still?) use Evernote? Or would that be too much sprawl? Could one build a structured data personal knowledge graph with it?
How about the people who do “quantified self” tracking and measurements of their own bodies - seems like the personal log would be a good place to store that instead of some proprietary database. If your doctor could pull up your Apple Watch’s heart rate history and correlate that with the physician-kept medical records it seems like they could do some cool things.
What about all the pictures and video I take (particularly of my family); wouldn’t that be a good data stream to add to the personal log? Would it be easy to share data streams with say my wife or other family members?
Challenges
There are plenty of difficulties to be addressed in building a system like the above.
“Worse is better” is an obvious consideration. Adding schemas to data opens up new possibilities, but the sheer simplicity of plain text remains empowering. The fact that Unix commands are still primarily strung together with plain text after half a century should be a testament to that.3 For this reason untyped data would still need to be supported in the personal log.
Security is another consideration. Like email, having an account stolen or forgetting credentials would be a very bad thing to happen. But when you’re adding fine-grained medical and financial data the stakes are much higher.
Further, deciding on schemas to use for the data could be a bit tricky. Schema.org does a good job with certain properties, although it’s not the only ontology in town.
Looking at medical data in particular, there would certainly be difficulties syncing up the different formats of electronic medical records (EMR), although in the US, the National Library of Medicine has created the Unified Medical Language System (UMLS) which does unify some of it.
Bank account ledgers would also have all kinds of different formats between banks and across international boundaries.
Yet, it would be interesting to see if the need for such a system would create incentives to unify some of this data that before seemed unlikely to ever be unified. If the Web can do it, why can’t this?
-
I’m conflating “log” and “database” in some areas which I realize. A “personal database” is probably more accurate, with certain features that behave like a “log” (the public writable part, and being able to share keyholed queries with others which behave like a stream, etc.), but the log is the interesting part so usually I’m primarily going to use the word “log.” ↩
-
Although that new shell Nushell seems interesting, and I’ve heard good things from Windows people about Powershell. ↩