
Why I’m switching from AWS to Google Cloud (GCP) for new personal projects

This post is about why I have taken a preference for Google Cloud (GCP) for developing web apps, as contrasted with my experiences using AWS. This is not meant to be an exhaustive comparison between the two, but rather what stands out to me as an application developer.
Introduction
Over the last few years, I’ve used AWS pretty regularly both for my job1 as well as for personal projects. My job in particular made pretty heavy use of AWS and I learned a lot there.
My only other cloud provider experience was about a year ago, when I briefly tried out GCP’s Kubernetes Engine (GKE) service in order to play around with Kubernetes (which I enjoyed). However, Cloud SQL’s lack of Postgres support made GCP a non-starter for me.
Fast forward to the present and I no longer work at an AWS-heavy job, GCP finally supports Postgres on Cloud SQL, and Kubernetes keeps getting better at managing Docker application deployments. Therefore I decided to give GCP an earnest try for a side project I’ve been working on, and I’ve been impressed to the point where I will be defaulting to GCP for future personal projects I start. Here are some reasons why.
What I like
Kubernetes

This is at the top of my list because it’s what really drew me in to GCP to start with. We all love Docker for giving us a standard way to build and run images/containers of our applications, but Docker didn’t come with a good production story.2
AWS created the Elastic Container Service (ECS) to address this, but I had a pretty poor experience using ECS and wouldn’t recommend it.
Kubernetes (K8s) is what sufficiently addresses the production deployment problem IMO, although it comes with new tools, concepts, and primitives that you need to learn (e.g. kubectl, Pods, Deployments, etc.). It has won out over its competitors (e.g. Mesos) and will be something more and more programmers will be learning.
However, K8s itself is a complex piece of kit that I wouldn’t want any part of installing, managing, or upgrading.3 Hence, a managed K8s install à la GKE, which also properly maps K8s resources to GCP services (e.g. Ingresses -> GCP load balancers, custom metadata annotations for static IP addresses, etc.), is the perfect solution.
It’s worth noting K8s itself was created and open sourced by Google (with ownership released to a neutral foundation), being based off of its internal tool of similar functionality called Borg. So it’s no surprise that (IMO) the best managed K8s solution comes from Google itself.
That said, AWS very recently announced managed Kubernetes as a service, but it’s still in Preview mode and will probably take a while to catch up to GKE’s ease of integration. Still, that’s excellent news.
Price
I don’t know where things stand with the latest price reductions, but if you google cloud provider cost comparisons GCP is generally regarded as cheaper than AWS (some are vocal). It can be tough to compare cloud providers since many services can’t simply be compared as 1:1 equivalents, and depending on your unique use case, those differences can be magnified, leading to cost disparities from one person’s experience to another.
All I can say is that for myself, I ported a small AWS web app (ECS/EC2, RDS, S3, CloudFront, Route53) over to GCP and my bill dropped from ~$150/mo to ~$100/mo. YMMV; compare pricing calculators yourself.
One nice difference though is GCP’s take on VM instance pricing compared to AWS. With AWS, the main way to cut VM instance costs is buying reserved instances, which locks you into a commitment to run a VM for a certain length of time. If later you realize you don’t need the instance, tough cookies - in theory you can sell the instance on the Reserved Instance Marketplace but you can’t always find a buyer, and some instance types like RDS cannot be sold on the Marketplace at all (I found that one out the hard way).
With GCP, you get a similar discount to AWS’s reserved instances simply by running the VM for an extended length of time - no upfront commitment needed. GCP calls this a “sustained use” discount. On top of that, GCP does also offer the reserved instance / contract-style discount in 1-3 year terms, which it calls “committed use” discounts.
In addition, Compute Engine (GCE) gives recommendations about shrinking underutilized instances to save money:
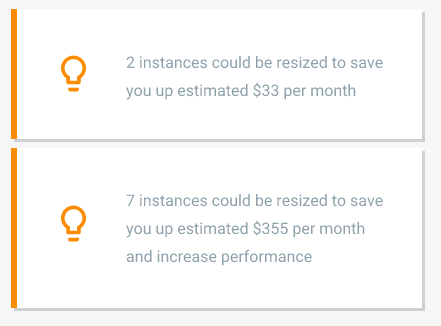
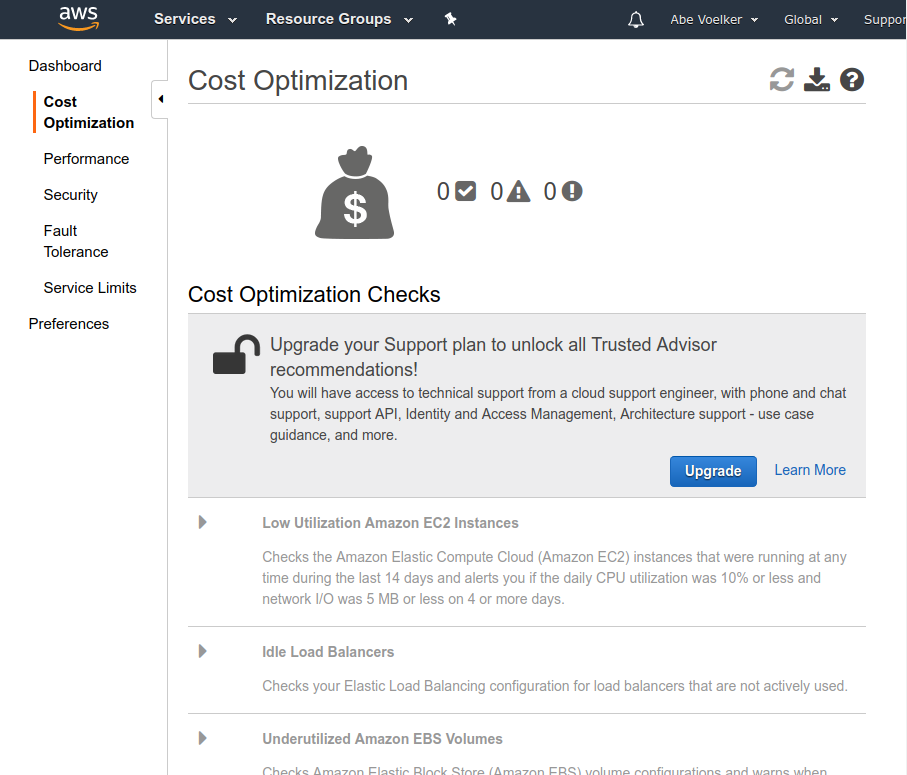
AWS offers a similar function via their Trusted Advisor, but it’s not free - cost optimization checks require a paid Business or Enterprise support contract to unlock:

Load balancers
One of the most important pieces of infrastructure in a web app is the application load balancer, as it’s the bottleneck between the world and your application servers.
AWS always made me cringe because their elastic/application load balancers (ELB / ALB) are bad at dealing with traffic spikes. You are supposed to anticipate flash demand (!) and contact customer service to “pre-warm” your ELBs (see anecdotes here and here). Very recently AWS got a new Network Load Balancer that is supposed to be capable of handling tens of millions of requests per second, however you’re limited to raw TCP termination (no HTTP/HTTPS).
GCP’s load balancing is supposedly much, much better at handling traffic spikes than ELB/ALBs. Google has a tutorial blog post (caveat emptor) back from 2013 showing their load balancer easily handling 1M requests/sec with reproducible instructions. In 2016 Google released a whitepaper on their implementation, which they call Maglev.
Centralized logging
It still amazes me that AWS releases a bunch of new products every year but still doesn’t have a good centralized logging story. In name CloudWatch Logs sounds like it should do that, but it doesn’t, and AWS’s solutions page on centralized logging4 shows they don’t have any illusions about that either (their solution is a tutorial on setting up Elasticsearch + Kibana).
So on AWS, if you want a managed solution (i.e. you don’t want to deploy/administer your own ELK stack), you end up paying for a SaaS service such as Splunk, Papertrail, Sumologic, etc.
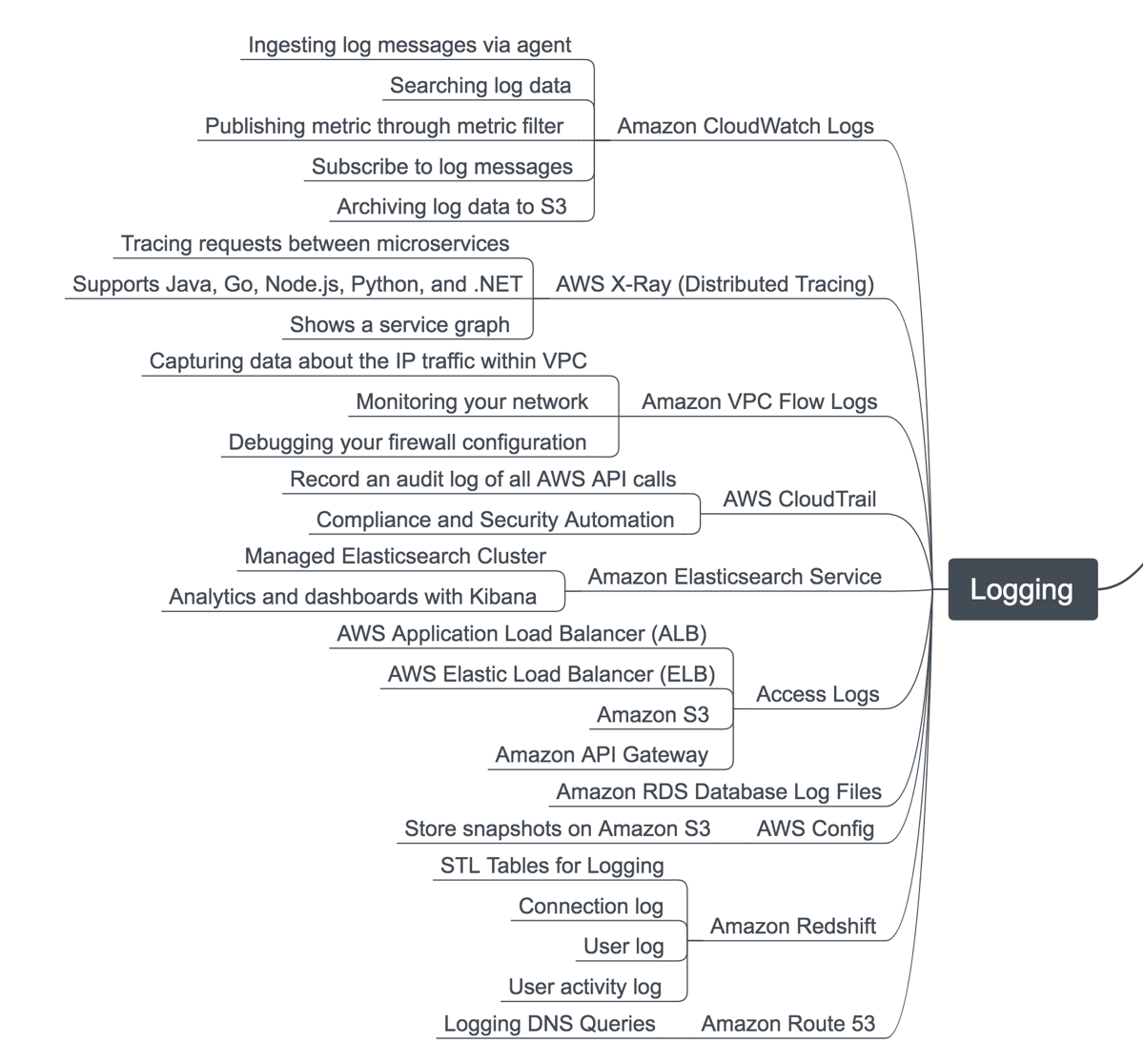
In addition, not every AWS service has good logging visibility. For example, to see ALB/ELB logs you have to first enable enhanced logging, then the logs get dumped in compressed format to an S3 bucket (which you pay storage costs for) which you then have to decompress, parse and query yourself. Here’s a good blog post on AWS monitoring that has a nice infographic which highlights various AWS log sources you’ll have to forward to whatever is aggregating/centralizing your logging:
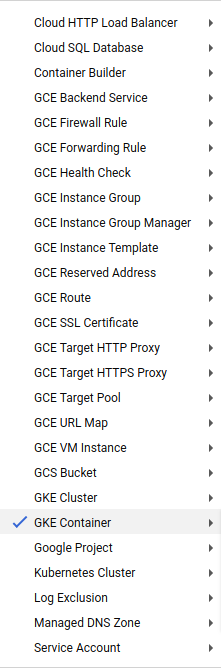
GCP’s Stackdriver Logging, meanwhile, comes with not only excellent application log aggregation and querying built-in, but also logs of the various GCP-managed services, such as GKE cluster logs, load balancers, and even Cloud CDN logs. Here is the dropdown I see in Google Console of the available log types:
GKE Cluster logs for example can give you useful insights into what K8s is doing:
I recently tried Kubernetes Audit Logs on GKE and it worked super smoothly.
— Ahmet Alp Balkan (@ahmetb) January 8, 2018
There’s so much to write about this, but here’s a quick example: pic.twitter.com/np49E0gmdc
Here’s what the Logging interface looks like, with one log line expanded showing logging metadata:
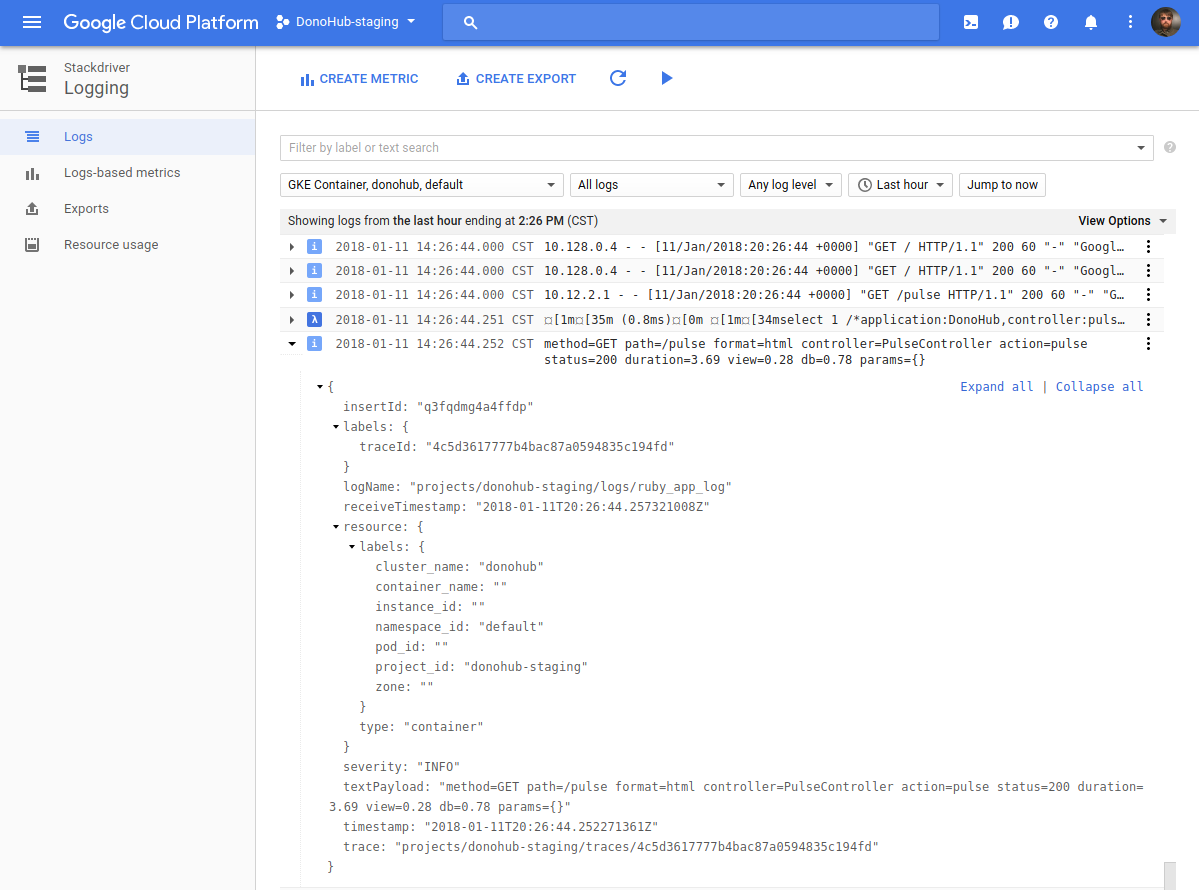
Stackdriver Logging comes with a pretty decent free tier at 50GB/month of storage and 7 days of retention (good enough for my projects). You can pay more for 30 days retention and more storage, but at $8 per instance it could get spendy.
Error notifications
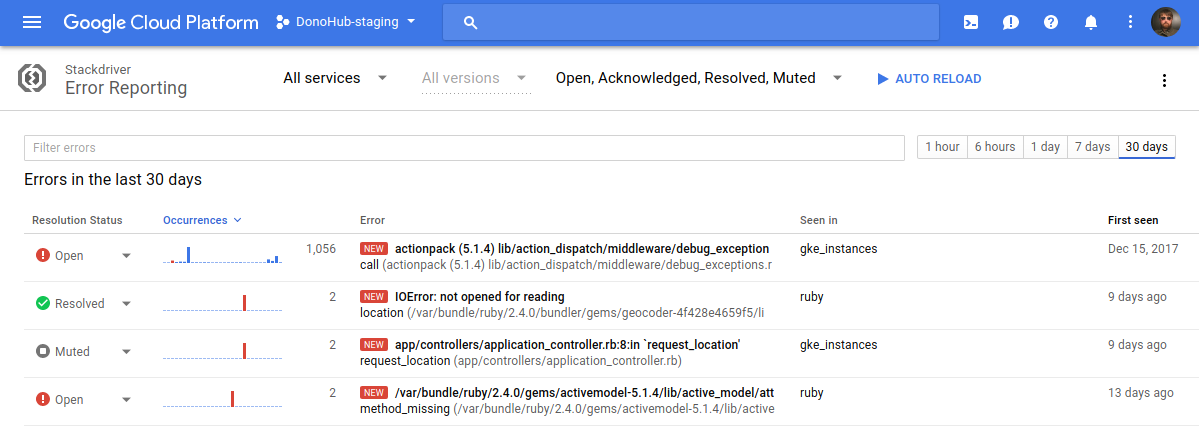
In addition to logging, Stackdriver also does error reporting. Support varies by language,5 but for Ruby there is a gem which will catch runtime errors and forward them to the error reporting service. You then receive emails when a new error occurs. Here’s an example:

Then in the Console you can acknowledge, mute, mark errors as resolved, etc.
Clicking on an error gives you a graph of occurrences, a list of recent occurrences, links to jump to Stackdriver logs, etc.:
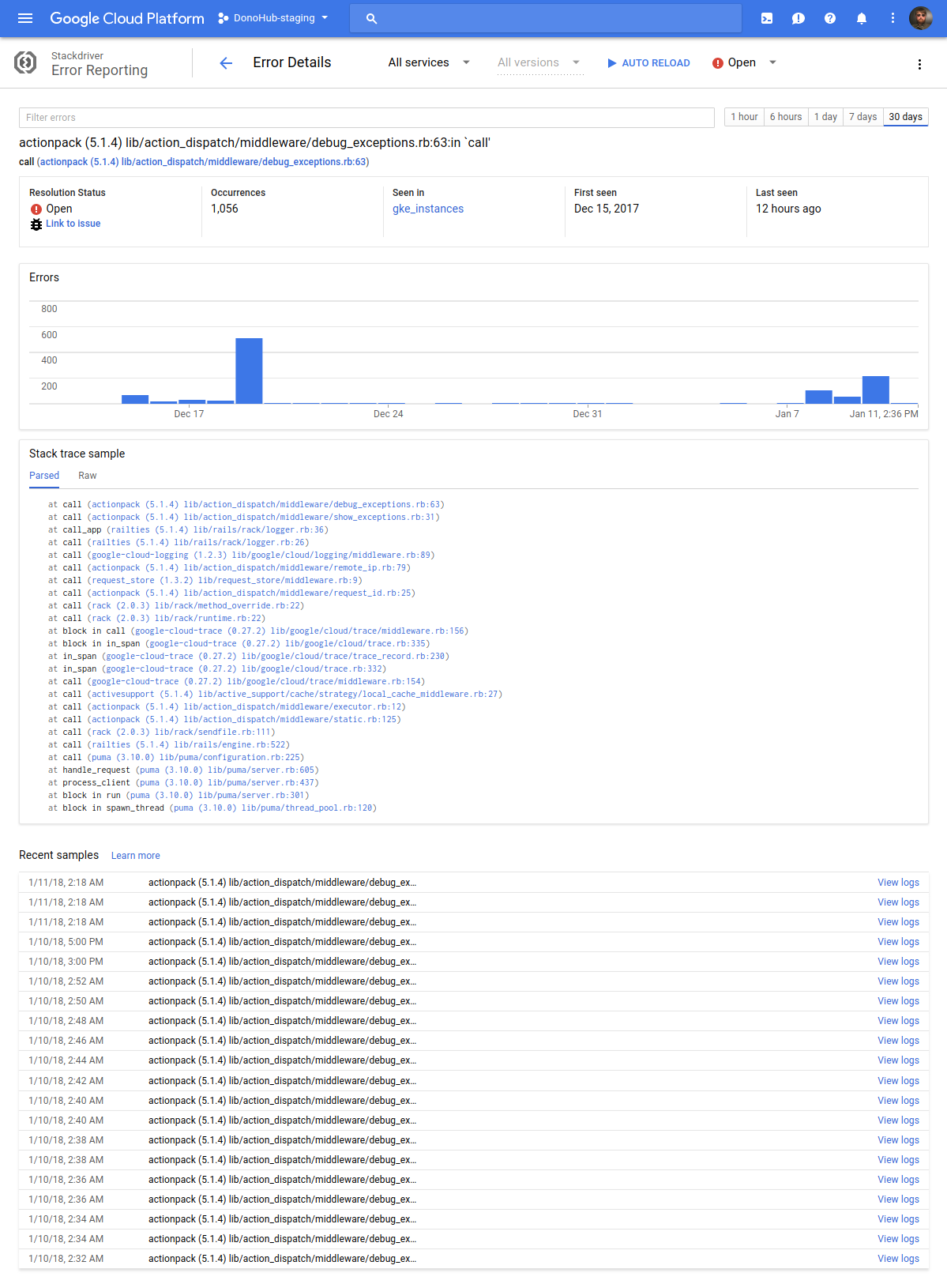
So far, this has been working well enough for me that I don’t have to pay for an error reporting SaaS like Sentry, Rollbar, or BugSnag like I typically would. And right now it’s all free while the product is still in beta.
I don’t think AWS has a direct equivalent to this. You may be able to cobble something together by creating a CloudWatch Logs metric filter, and creating an Alarm on that, but it would be hacky and brittle.
There are also other Stackdriver products, like Trace, which tracks latency across URIs to help find bottlenecks, and Debugger, which is supposed to enable real-time production debugging, but I haven’t spent much time with either product yet.
Security
There’s a trite meme about the cloud simply being “someone else’s computer.” While that’s terribly reductionist, it’s true that if you’re using a cloud provider like GCP you’re putting all of your (and your users’) data on their computers. That certainly requires a great deal of trust - have they earned it?
Let’s start with a flashback to the Snowden leaks. Remember this leaked slide on NSA’s MUSCULAR program?
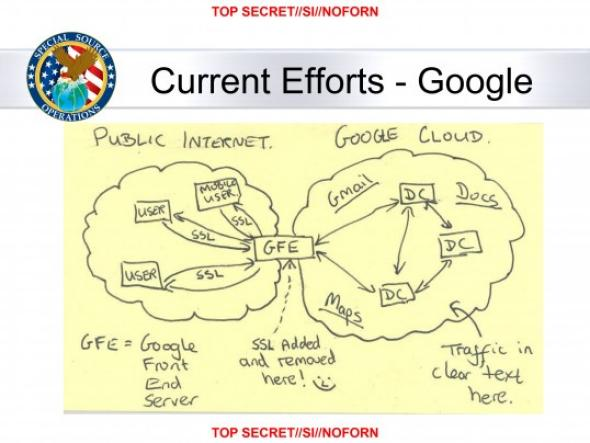
While NSA was :^), Google’s (unofficial) reaction seemed to be more like ┻━┻ ︵ヽ(`Д´)ノ︵ ┻━┻
Google seems to have learned its lesson, as GCP by default encrypts all data in transit as well as all data at rest. When I checked on what AWS does, it seems that encryption at rest availability depends on the service and often requires user intervention to enable (not a default setting), however they do claim “encryption in transit with TLS across all services.”
GCP’s handling of the recent catastrophic speculative execution vulnerabilities in the vast majority of modern CPUs (Meltdown, Spectre) is also instructive. Google developed a novel binary modification technique called Retpoline which sidesteps the problem and transparently applied the change across running infrastructure without users noticing. Rather than keep Retpoline a trade secret, they open sourced their implementation and shared it with industry partners.
GCP also was able to hot patch running VMs that use their OS images without requiring a reboot using their live migration feature. This only works when using GCP’s OS images though; people who run their own are on their own.
AWS’s handling of the speculative execution vulnerabilities required users to reboot their VMs after updating to the latest AMI version as they don’t have a feature similar to live migration.
It’s also worth noting that Google itself, through its Project Zero group, was a co-discoverer of this set of vulnerabilities. Project Zero was established after the earth-shaking Heartbleed vulnerability was uncovered in an attempt to prevent a repeat. I like that supporting GCP also helps support a proactive bug-hunting effort like Project Zero.
For its own part, although AWS doesn’t have a bug-hunting security research group like Project Zero to my knowledge, they did help contribute retpoline patches to the upstream Linux kernel.
Cloud Storage
If you host public files on an S3 bucket as assets (e.g. for a blog), ideally you shouldn’t use bare S3 URLs, because S3 is not a CDN (no geographically-aware caching) so you will get variable latency responses. The ideal way is to put a CDN (say, CloudFront) in front of your S3 bucket and share the CDN-ified URLs. Extra credit for putting up a bucket policy that prevents anyone but your CDN from hitting your public S3 bucket.
GCP’s equivalent to S3 is called Cloud Storage. This is a minor thing, but Cloud Storage makes it much simpler when linking to publicly readable objects because they are already CDN-ified, so you can just share the public Cloud Storage URLs - no extra CDN setup needed!
However, there is one thing that needs work with Cloud Storage, which is using a custom domain name while serving your content over HTTPS (cough like this blog cough). Currently, Cloud Storage doesn’t easily support that; it requires you to pay for a load balancer ($) or use a third-party CDN:

Meanwhile in AWS, you can easily create a TLS-enabled CloudFront distribution to serve content from S3 buckets. So my blog will stay on AWS S3+CloudFront until GCP gets a better story for this use case.
Resource Hierarchy
This is also a minor thing, but I really like the project organizational feature that GCP provides. Projects are one part of a whole resource hierarchy that GCP defines, which includes other pieces like folders and organizations, but since I’m a lone developer I find projects most useful.
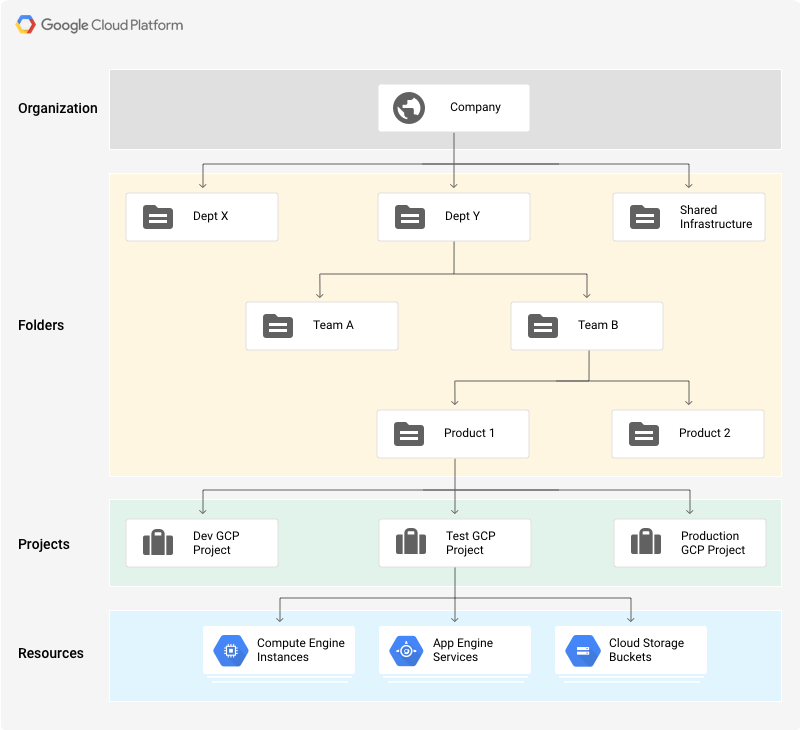
Here’s why: with AWS, if you want to say run multiple environments of a web app under the same AWS account, you have to name your resources carefully so that they don’t collide (e.g. foo-staging, foo-production, etc.). Billing also gets complicated - you have to add tags to every resource so that you can properly track things in the billing view. Finally, it can be dangerous - you have to be very careful when destroying resources, setting up VPCs + ACLs or Security Groups, etc. lest you fat-finger something and destroy or blackhole a prod resource. Or if some errant test process hits an AWS service limit and a production service ends up getting throttled.
Therefore it’s common with AWS to create entirely separate AWS accounts per environment, which traditionally has been a slight headache, but I think has gotten better since AWS added organizations and other cross-account features.
Using GCP projects, meanwhile, I can simply create a separate project per environment and everything is nicely segregated without any additional overhead. I don’t have to namespace resources, billing all goes to the organizational account, and service quotas are scoped to the project level so I don’t have to worry about prod getting throttled by an errant QA process.
Documentation and support
Both GCP and AWS have pretty good documentation in my experience. I appreciate that both providers provide a lot of tutorials with precise console commands to walk through common use cases.
One thing I like about GCP’s documentation is that each service has a “support” section that has links to open support resources like specific StackOverflow tags or Google Groups message boards to post in. Here’s Cloud SQL’s support section for example:
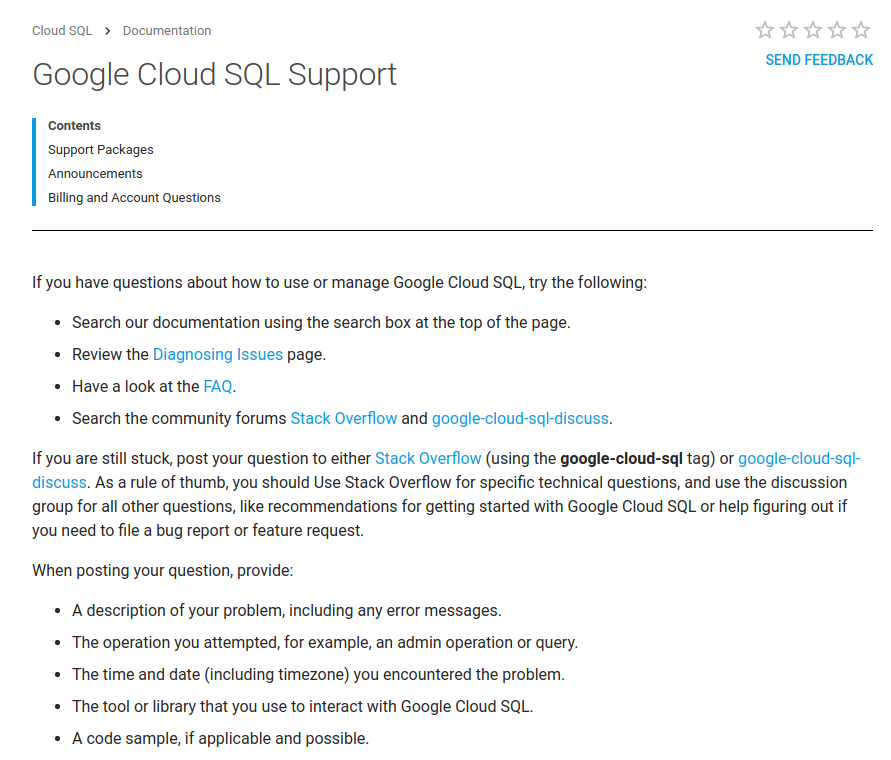
I like that GCP acknowledges that not everyone is going to pay $150+/mo for premium support and links to free/open resources. Check out this big infographic of free support resources on their main support page:
Speaking of support, I don’t have any experience using paid support with either provider. For personal projects I don’t have the money for it, and at my day job someone else handled official support tickets.
However, over the past month I’ve used a few of GCP’s free support resources and I’ve been impressed so far.
The first was their official Slack channel, when I was having an issue with Cloud CDN being slow / apparently not working. I got some responses from a GCP employee (@tscanausa, who seems to idle there often) who at least helped me do some sanity checks and confirmed I wasn’t doing anything obviously wrong. It wasn’t free end-to-end support and didn’t resolve my problem, but was helpful nonetheless. (Later questions I’ve asked are sometimes met with crickets though so YMMV)
The second was asking a question about Container Builder on Stack Overflow, which I then realized the answer to myself shortly afterward and self-answered. That answer got a few upvotes not long after I posted, which I thought was weird since not many people probably interact with that product. But after looking through the google-cloud-platform tag I noticed a lot of questions were getting answers from GCP employees (looking at profiles), so there’s a noticeable official presence there. Which should be expected I guess since I noted above that there are official support tags that GCP links to from products’ support pages.
The last I used was opening several feature requests / bug reports on their issue tracker. Every one I opened got attention from an employee asking for more information and triaging the issue internally, which was nice.
AWS’s open support channel is their community forums, which in my own experience has been pretty hit or miss with getting any response, much less acknowledgement from official staff.
AWS also has a StackOverflow tag (amazon-web-services), although they don’t advertise it anywhere in their documentation or product pages that I can see. Compared to GCP’s tag, it has a noticeably higher volume, with the total number of questions being about 10x higher than GCP’s (~50K vs ~5K). My very unscientific test of scrolling through the “newest” questions for both tags shows that GCP’s has a way higher answer rate, with a lot of answers coming from GCP employees, whereas AWS’s has a lower answer rate, and while there are some AWS employees answering, there are more random AWS consultants/advocates/evangelists that answer.
Roles
Roles are how GCP handles permissions - they’re roughly the equivalent of AWS’s IAM policies. I almost dinged this aspect of GCP because when first learning it I got a bit tripped up by some differences from how it does things compared to AWS, but that was my own fault for clinging to my preconceived AWS mental model. After chatting with a reviewer of this post, I agreed with him that this is actually rather nice compared to AWS.
First, a reminder that AWS handles permissions through IAM policies.6 These policies are JSON documents that let you specify in detail precisely which IAM user/account/service (the “Principal”) is allowed or disallowed to perform a set of fine-grained actions against a list of specific resources.
These JSON documents can get a bit complicated to assemble by hand, so AWS has a policy generator, a policy syntax validator, and even an IAM policy simulator, as well of course various examples to look at.
GCP’s approach is a bit different. Instead of having you select a bunch of fine-grained permissions à la carte, they bundle related permissions into predefined groups called “roles.” For example, here’s the table of Cloud SQL roles:

One thing that really tripped me up at first is that a lot of services - including Cloud SQL in the above screenshot - can only target an entire project or organization rather than specific resources (e.g. one database instance).
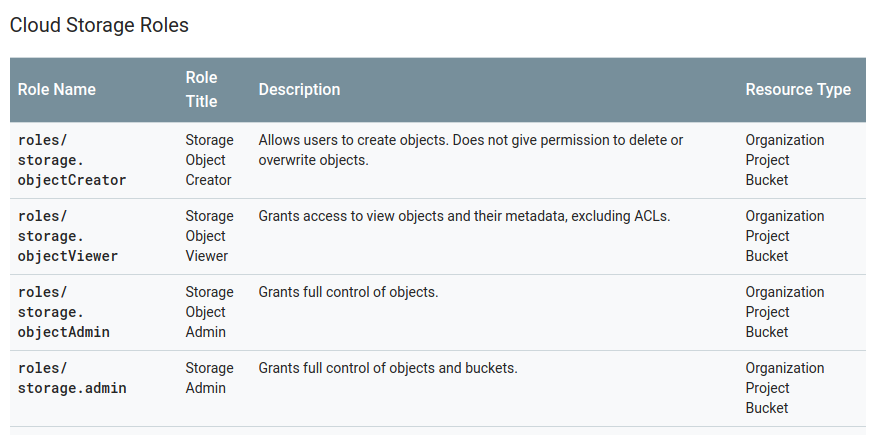
Some resources do have that granularity, however - for example, here’s Cloud Storage, which lets you target individual bucket resources:
Behind the scenes, these roles are hiding a bunch of fine-grained IAM permissions; for example, here’s a truncated list of what the GCE’s instanceAdmin role bundles up:
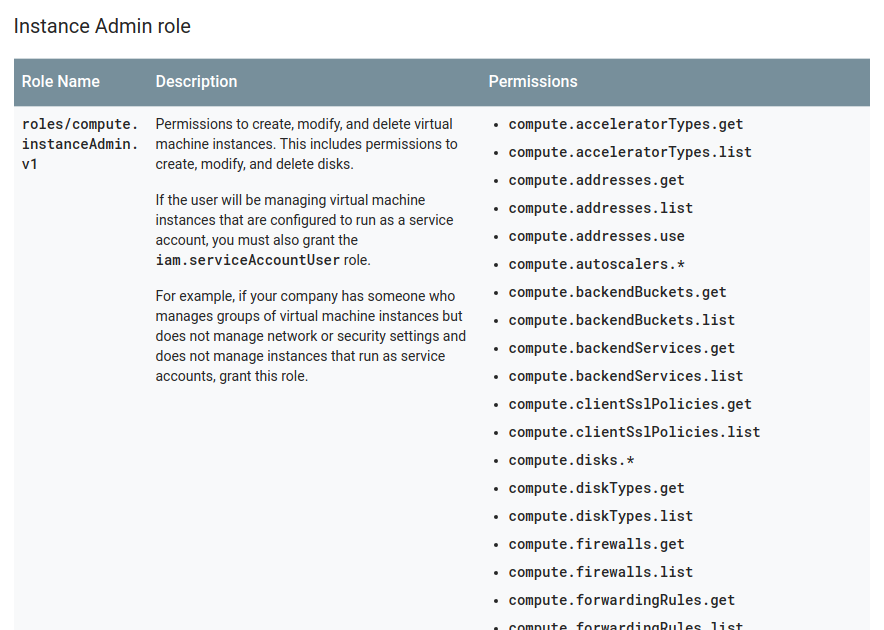
In practice so far this has been a lot easier to manage for me, versus before with AWS having to dynamically generate various JSON blobs from templates in my deployment process. So far I have not needed access to fine-grained IAM permissions, but GCP does currently have that as a Beta feature called IAM Custom Roles.
What needs improvement
I’ve listed a lot of things I like, but it’s not all 🦄s and 🌈s:
No Certificate Manager
AWS has a very nice service for managing SSL certificates called AWS Certificate Manager (ACM). After verifying ownership of a domain, ACM generates certificates for you and allows you to attach them to load balancers or CloudFront distributions. AWS can do this because Amazon is a browser root certificate authority (CA). ACM handles renewing certificates and re-attaching them to your load balancers / CloudFront so you don’t need to worry about certificate expiration ever again!
GCP meanwhile only offers this kind of managed SSL certificate service for App Engine apps. You’re out of luck if you use GKE or Cloud CDN. Instead, GCP tutorials punt you over to Let’s Encrypt. Which, combined with kube-lego if you’re using GKE isn’t horrible, but still a far cry from a fully managed service - you still have to keep an eye on kube-lego to ensure that renewals are working.
I’ve opened a feature request to ask GCP to add managed SSL certificates for general purpose use (⭐️s appreciated!).
Cloud SQL Proxy
Weirdly, GKE makes you access your Cloud SQL instances using a “Cloud SQL proxy” sidecar container rather than simply directly connecting from your application container using an IP address and port.7
This proxy sidecar container works fine for normal Deployment use, but unfortunately there is some bad K8s behavior when defining CronJob and Job resources with sidecar containers that turns it into a horrorshow:
- https://github.com/kubernetes/kubernetes/issues/25908
- https://github.com/GoogleCloudPlatform/cloudsql-proxy/issues/128
I filed a feature request to improve this situation (⭐️s appreciated!).
Cloud CDN for GKE
This is probably very specific to my setup but as I’ve mentioned in the support section, I’ve run into problems integrating GKE with Cloud CDN, both with responses appearing to be cached (Age header present) yet getting very bad latency responses from my machine (and getting worse at more geographically distant locations), to responses not being served from cache that should be according to all troubleshooting steps.
This is something that I could probably resolve with a paid support plan - which I’m not going to spend $150 on for one issue - but not being able to resolve it myself seems like a ding on the quality of the product. It may just be an obscure GKE integration thing because Cloud CDN seems to review well when googling various CDN benchmarks.
Stackdriver integration issue debugging
I mentioned I liked the various Stackdriver services, but an annoying thing about integrating them is that the only debugging tool you have is the relevant API dashboard page that shows error and success counts:
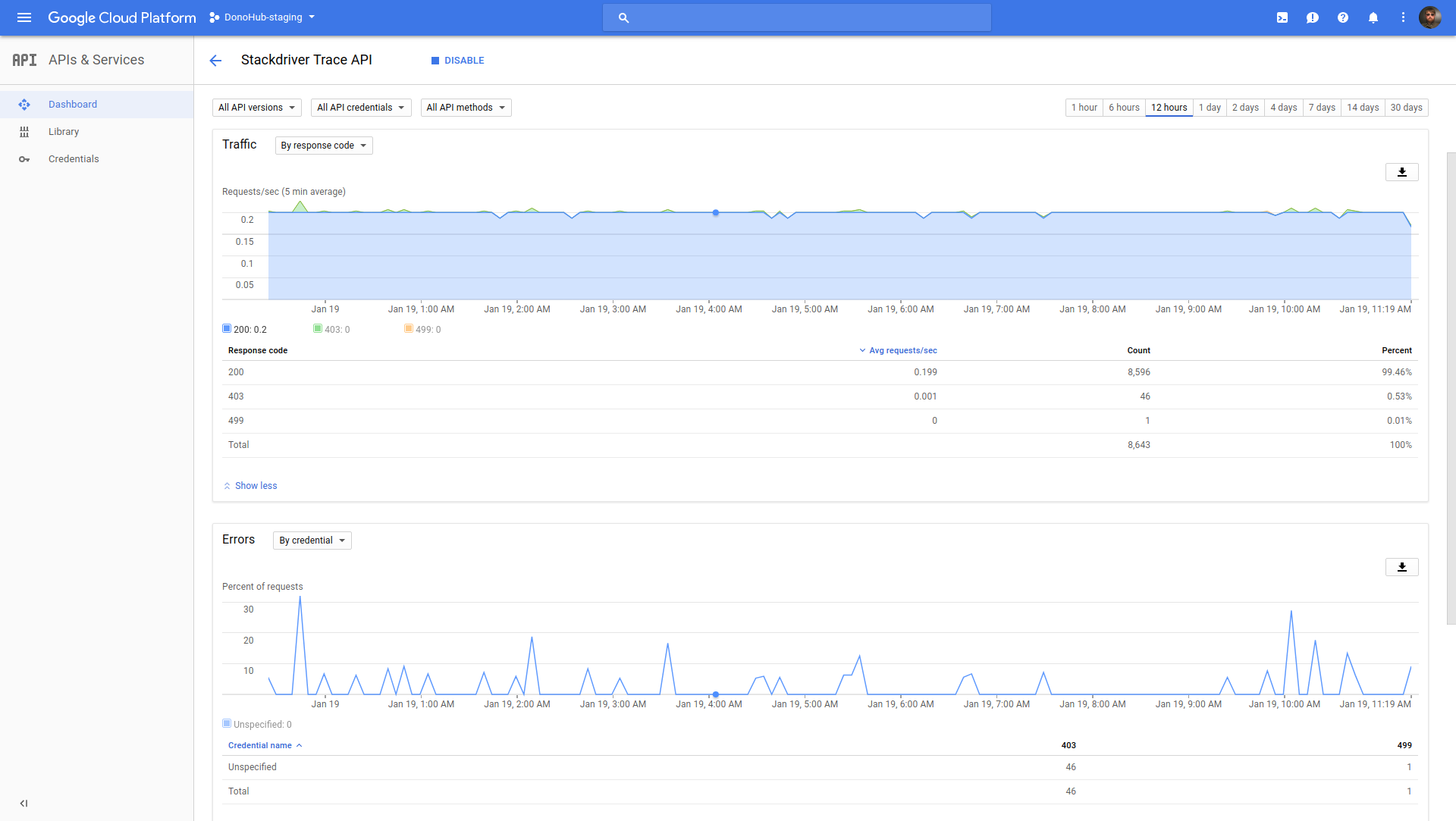
If you set it up wrong (like I did at first8), your error counts will be through the roof, and you have to try to suss out why purely from the HTTP code and credentials chart filters - there’s no logs to look at.
For example, I still have a ~1% error ratio on a couple Stackdriver services, and I’m not even sure what’s causing those errors:
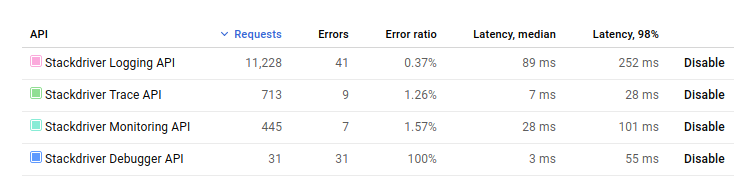
(The 100% error rate for Stackdriver Debugger I’m pretty sure is because I don’t have a permission set correctly on my GKE cluster, but again with poor visibility into the problem, I’m left guess-and-checking)
Conclusion
Hopefully I’ve demonstrated how GCP’s products achieve a better fit for the way I develop web applications than AWS. I hope I’ve been fair to show that GCP is not strictly better than AWS - just for my needs - and in fact could stand to improve on some things. As I continue to use GCP I’m sure I’ll find more things that frustrate and/or delight me.
Also, to be fair to AWS, it’s worth mentioning that for some products GCP has had the benefit of AWS’s implementation being first, and being able to see what worked or didn’t work. Then again, AWS is also learning some lessons from GCP (managed K8s, Network Load Balancer). Competition is good!
✌️
Thank you 😍🤩🙇
Thank you to Sunny R. Juneja (@sunnyrjuneja) and Daniel Brice (@fried_brice) for reviewing drafts of this post and providing feedback!
All mistakes, bad opinions, and crude language in this post are of course solely my own and do not reflect upon reviewers.
Fuck you 🤬😤🤫👀
A hearty fuck you to the group of shit-eating bastards who stabbed me in the back last year. You know who you are.
1 All opinions my own and nothing to do with previous or current employers
2 From low-level concerns like managing cleanup of images and containers, to higher level concerns like rolling deployment strategies, service discovery, stateful services, maximizing physical resource usage when allocating containers, storing secret values, etc.
3 If you have to, however, Kelsey Hightower has a great tutorial and book on the subject (amongst many other amazing resources he’s provided to the community)
4 The top Google result for “aws centralized logging”
5 The overview page says “The exception stack trace parser is able to process Java, Python, JavaScript, Ruby, C#, PHP, and Go”
6 Well technically some resources have their own policy types, like S3 buckets
7 Well, unless you want to go over the slow public WAN and incur network costs
8 Protip for GKE: make sure you add the right scopes when creating your cluster